A small history on Large block sizes in Linux: Part 3
This is a multipart series where I will be going over the support of Large block sizes(LBS) on Linux. Take a look at the previous articles from LBS series before proceeding with this article.
In this blog post, we will cover the implementation of the latest round of LBS patches that have been sent to the Linux kernel which are in the process of getting mainlined soon. For more context:
Just to reiterate the issue with LBS support on Linux:
- Historically, page cache was closely tied to system page size.
- No support to track the “blocks” > page size as a single unit in the page cache to avoid eviction of partial blocks.
Glossary:
Order of page: order N means you have 2N pages grouped together.
Folio: A structure that can represent one or more pages, but it represents either order-0 page or the head page of a compound page (large folio).
xarray: data structure introduced to manage dynamic, sparse array efficiently. It replaces the older radix tree data structure for many use cases.
iomap: Filesystem library for handling common file operations.
Large folio support in the page cache:
Page cache got the support for large folios in Linux 5.18. This support creates large folios in the readahead and fault paths when the filesystem enables large folios mapping. The first filesystem to enable this was XFS. Note that this is an optimization based on the size of the readahead and the memory pressure.
This support is really crucial for LBS as page cache is not any more tied to a single “PAGE” anymore.
Matthew Wilcox on why large folios is important for LBS support on Linux:
The important reason to need large folios to support large drive block sizes
is that the block size is the minimum I/O size. That means that if we're
going to write from the page cache, we need the entire block to be present.
We can't evict one page and then try to write back the other pages -- we'd
have to read the page we evicted back in. So we want to track dirtiness and
presence on a per-folio basis; and we must restrict folio size to be no
smaller than block size.
Missing piece in the puzzle for LBS XFS:
iomap already supports large folios, and it got further optimizations to create large folios in the buffered IO write path. XFS used to support LBS when it was a part of IRIX, and it lost that support when it was ported to Linux.
The only missing piece to add LBS support to XFS was the ability of the filesystem to request minimum order of allocation in the page cache. With the minimum order support in the page cache, the filesystem can allocate blocks that are greater than the page size to be tracked as “one” unit.
Dave Chinner on what was missing for LBS support:
the main blocker why bs > ps could not work on XFS was due to the
limitation in page cache: `filemap_get_folio(FGP_CREAT) always allocate
at least filesystem block size`
 |
|---|
| Minimum folio order support built on top of Large folio support |
Minimum folio order support to page cache:
Minimum folio order support is added to the page cache so that:
- Filesystem can indicate the preferred folio order during inode init. Typically, it should correspond to the filesystem block size.
- Page cache will always respect this constraint while adding new folios to the page cache.
The following diagram shows the changes in the page cache with large folio support and minimum folio order support:
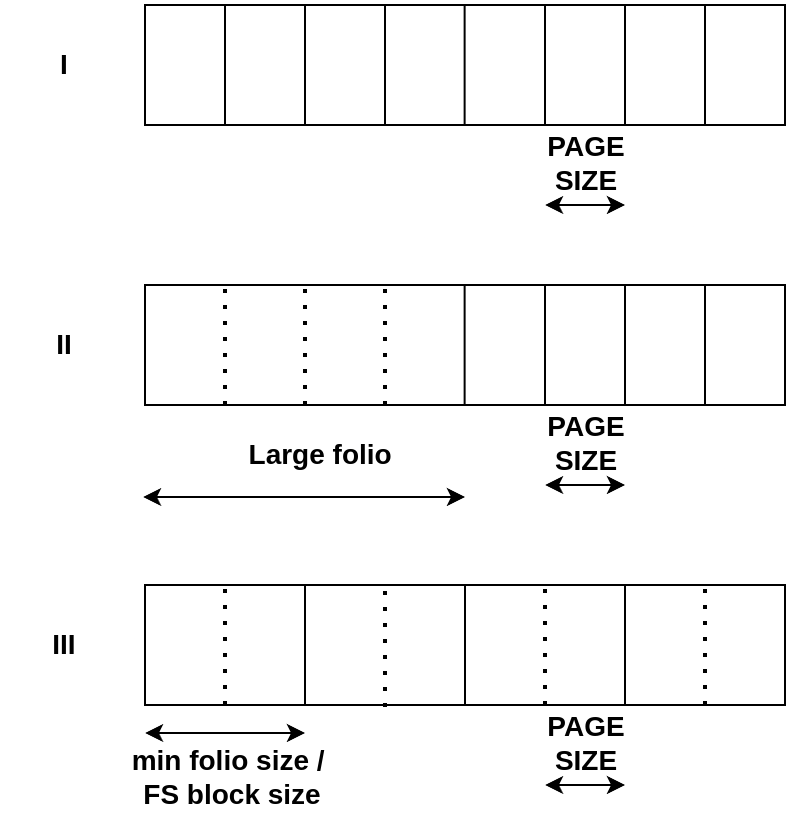 |
|---|
| Page cache with (I) no large folio support (II) Large folio support (III) Minimum folio order support |
API:
mapping_set_large_folios() was already present since 5.18 where
filesystems can opt in for large folios optimization in the page cache.
As a part of this patch series, mapping_set_folio_min_order() and
mapping_set_folio_order_range() has been added.
static inline void mapping_set_large_folios(struct address_space *mapping)
static inline void mapping_set_folio_min_order(struct address_space *mapping, unsigned int min)
static inline void mapping_set_folio_order_range(struct address_space *mapping,
unsigned int min,
unsigned int max)
For most filesystems, it is enough to use
mapping_set_folio_min_order() to set the minimum folio order and
max folio order can be inherited from the page cache. For filesystems
that want to also control the maximum folio order,
mapping_set_folio_order_range() can be used to control both the min
and max.
We encode the folio order information in the flag member from bit 16
to 25 of the struct address_space:
enum mapping_flags {
...
AS_EXITING = 4, /* final truncate in progress */
...
/* Bits 16-25 are used for FOLIO_ORDER */
AS_FOLIO_ORDER_BITS = 5,
AS_FOLIO_ORDER_MIN = 16,
AS_FOLIO_ORDER_MAX = AS_FOLIO_ORDER_MIN + AS_FOLIO_ORDER_BITS,
};
struct address_space {
struct inode *host;
struct xarray i_pages;
...
unsigned long flags;
...
};
Implementation:
There are some cases where the kernel will try to break a huge page into individual pages, which can break the promise of minimum folio order. The main constraint that is put on the page cache with minimum folio order support is to always ensure that the folios in the page cache are never lower than the minimum order.
Folio allocation and placement:
Page cache uses filemap_alloc_folio and filemap_add_folio to add
allocate and add folios in the page cache. xarray is the data
structure that is used to manage the page cache. xarray has a
limitation on the alignment when higher order folios are added. The
folio index should be naturally aligned with the order of the folio.
If we are adding a folio of order 5, which corresponds to 32 pages, then the index should be a multiple of 32.
The following helper was added to make sure the alignment is respected before adding a folio to the page cache:
/**
* The index of a folio must be naturally aligned. If you are adding a
* new folio to the page cache and need to know what index to give it,
* call this function.
*/
static inline pgoff_t mapping_align_index(struct address_space *mapping,
pgoff_t index)
{
return round_down(index, mapping_min_folio_nrpages(mapping));
}
The following steps are done in all the places where a new folio is added to the page cache to ensure they are allocated and aligned in minimum folio order.
// Allocate a folio with minimum folio order
folio = filemap_alloc_folio(gfp, mapping_min_folio_order(mapping));
...
// Align the folio index with min order
index = mapping_align_index(mapping, index);
...
// Add the folio with the correct order and alignment
err = filemap_add_folio(mapping, folio, index, gfp);
Split folio:
When a large folio is partially truncated(truncate_inode_partial_folio()), the page cache attempts to split it into smaller folios (single pages/order 0). The guarantee of minimum folio order will be removed if you split to 0 order folios.
split_folio() was modified so that the underlying call to
split_huge_page_to_list_to_order() is called with minimum folio order
if it is a file-backed memory.
#define split_folio(f) split_folio_to_list(f, NULL)
int min_order_for_split(struct folio *folio)
{
...
return mapping_min_folio_order(folio->mapping);
}
int split_folio_to_list(struct folio *folio, struct list_head *list)
{
int order = min_order_for_split(folio);
...
return split_huge_page_to_list_to_order(&folio->page, list, order);
}
The following diagram depicts the change in behaviour after having the minimum folio order support while splitting:
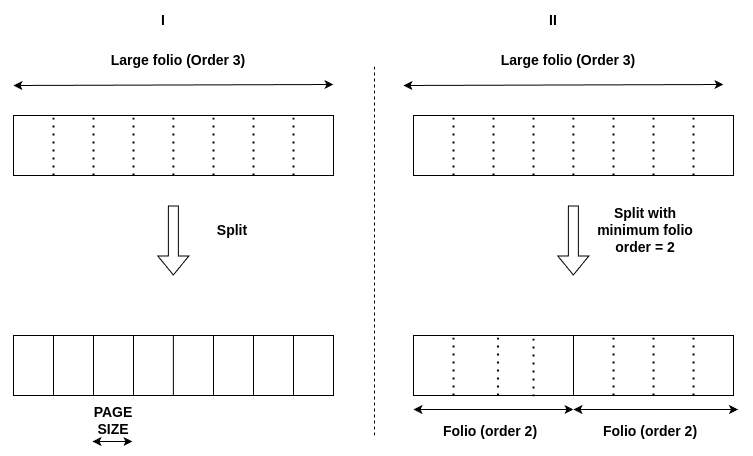 |
|---|
| Split folio (I) Normal behaviour (I) with minimum folio order support |
Upstream Bugs:
There were assumptions that had to be fixed as PAGE_SIZE has been the base unit in the kernel for a long time.
Consider the following example:We mmap a 4k file with length 8k. POSIX says that the kernel should return SIGBUS if we access from 4k to 8k as it is still a valid mmap region, and SIGSEGV from 8k onwards.
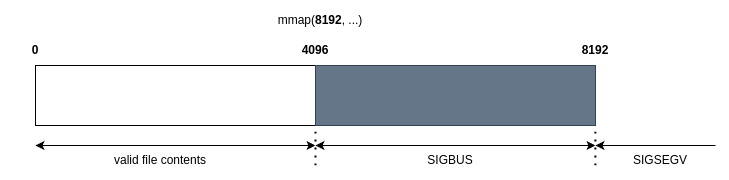 |
|---|
| Return behaviour for a 4k file that is mmaped with len 8192. |
Linux kernel has a special optimization called fault_around to map easily accessible pages
while taking a page fault (patch).
This can be tuned by fault_around_pages kernel debug parameter. It is
set to 64k by default.
Page cache never extended beyond End of a File(EOF). That changed
to maintain minimum folio order support where page cache might extend
beyond the EOF. This side effect along with fault_around optimization
resulted in LBS patches not complying with the error values according to
POSIX.
The following changes were made to accommodate LBS patches for fault_around:
vm_fault_t filemap_map_pages(struct vm_fault *vmf, ...)
{
...
file_end = DIV_ROUND_UP(i_size_read(mapping->host), PAGE_SIZE) - 1;
if (end_pgoff > file_end)
end_pgoff = file_end;
...
}
The above snippet clamps the end page offset of the page cache to EOF. There was a test added to xfstest to catch this corner case link.
iomap direct IO code uses a ZERO_PAGE to do sub-block zeroing. If the
FS block size is 4k, and we try to write 512 bytes, then iomap direct IO
helper iomap_dio_zero() will zero out the offset without any data.
iomap_dio_zero() will access page next to the ZERO_PAGE, which could
be undefined, if the block size > PAGE_SIZE. This can result in FS
corruption.
PAGE_SIZE assumption should be removed from iomap_dio_zero for LBS.
A compound zero page of size 64k is allocated during the iomap direct io
initialization. 64k is chosen because that is maximum filesystem block
size that is supported in Linux. That compound zero page is used to
perform sub-block zeroing instead of using a single ZERO_PAGE.
The initial implementation of this patch had a loop with ZERO_PAGE instead of
allocating a compound zero page. But compound zero-page approach was
taken as it is more efficient.
/*
* Used for sub block zeroing in iomap_dio_zero()
*/
#define IOMAP_ZERO_PAGE_SIZE (SZ_64K)
#define IOMAP_ZERO_PAGE_ORDER (get_order(IOMAP_ZERO_PAGE_SIZE))
static struct page *zero_page;
...
static int iomap_dio_zero(const struct iomap_iter *iter, struct iomap_dio *dio,
loff_t pos, unsigned len)
{
...
__bio_add_page(bio, zero_page, len, 0);
iomap_dio_submit_bio(iter, dio, bio, pos);
...
}
...
static int __init iomap_dio_init(void)
{
zero_page = alloc_pages(GFP_KERNEL | __GFP_ZERO,
IOMAP_ZERO_PAGE_ORDER);
...
}
Conclusion:
The presence of large folio support in the kernel greatly reduced the complexity of adding LBS support. This work is an accumulation of various efforts that have been made in the past LBS part 2.
The Kernel also needs this support to enable block devices with LBA size greater than the PAGE_SIZE as the block cache shares the same infrastructure as the page cache for filesystems.
Enabling LBS support in filesystems requires careful evaluation, and in some cases, filesystem changes. This series only enables XFS. Future work includes RAMFS, bcachefs, ext4, etc.
Happy reading!