A small history on Large block sizes in Linux: Part 2
This is a multipart series where I will be going over the support of Large block sizes(LBS) on Linux.
This article will cover the previous attempts at enabling LBS in the Linux kernel. There were three major efforts that I will be covering in this article:
- 2007: Christoph Lamenter posted Large Block Size support
- 2007 & 2009: Nick Piggin posted fsblock & fsblock v2.
- 2018: Dave Chinner xfs: Block size > PAGE_SIZE support
If you only care about the final attempt that made it upstream, then please refer to the next part.
This post will require some level of the Linux kernel internals
understanding.
Before reading this article, I would highly recommend
checking out Part1
section: Why the limitation on block sizes?.
2007: Christoph Lamenter posted Large Block Size support
The initial use case for LBS came from the CD/DVD world where the block size typically where in the range of 32k/64k. Lamenter sent patches to enable LBS by making changes mainly in the page cache.
The main idea was to use compound page allocation in the page cache to match block size of the device. The crux of the change is that we set the order of allocation in the page cache and make sure to always allocate with that order:
static inline void set_mapping_order(struct address_space *a, int order)
{
a->order = order;
a->shift = order + PAGE_SHIFT;
a->offset_mask = (1UL << a->shift) - 1;
if (order)
a->flags |= __GFP_COMP;
}
static inline int mapping_order(struct address_space *a)
{
return a->order;
}
...
static inline struct page *__page_cache_alloc(gfp_t gfp, int order)
{
return alloc_pages(gfp, order); // Before order was always == 0
}
This is a simplification of the patchset, but this is the main meat of the changes. We will see in the next blog that the current implementation resembles the approach taken 17 years back.
The patchset was rejected because it was adding more complexity to the core VM subsystem and the implementation could not handle faults on larger pages to make mmap() work. So the patchset just disabled mmap functionality if LBS was enabled, which is not great.
2009: Nick piggins posted fsblock
To understand the motivation of fsblock, first we need to understand the
struct buffer_head in the kernel. buffer_head structure tracks
buffers in memory. Buffers are in-memory copy of a disk block from a
block device. A logical disk block can correspond to multiple sectors in
disk. The main motivation from this series was to completely
rip out struct buffer_head as it is one of the oldest code that has
been in the kernel, but many filesystems use it. fsblock was an attempt
to improve the “buffer” layer which sits in between filesystem and a
block device.
One of the promises of fsblock rewrite was ability to support large
block sizes in filesystems. The maximum block size supported by
struct buffer_head is limited by the PAGE_SIZE of the system.
The PAGE_SIZE limitation is embedded by design in buffer heads,
especially the maximum number of buffers a struct buffer_head can hold is limited
by PAGE_SIZE.
Following is struct buffer_head[2]:
struct buffer_head {
unsigned long b_state; /* buffer state flags */
atomic_t b_count; /* buffer usage counter */
struct buffer_head *b_this_page; /* buffers using this page */
struct page *b_page; /* page storing this buffer */
sector_t b_blocknr; /* logical block number */
...
<snip>
};
The buffers are stored in b_page field. Even though we could store
compound pages in b_page struct, buffer_head was designed with
b_page holding a single page in mind. So a single buffer can be at
most a single page.(See MAX_BUF_PER_PAGE link)
Many filesystems at that time used the buffer_head structure to cache
the block device reads in memory. This lead to a limitation of the logical
block size of the underlying block device to be maximum of host PAGE_SIZE.
Similar to buffer_head, fsblock struct holds a disk block in memory, but it adds the concept of “superpage block” which could hold multiple blocks. Unlike buffer_head, fsblock does not have limitation on the size of the block, i.e, each disk block could be PAGE_SIZE and we can map multiple disk block with a single fsblock struct. This enables filesystems to have LBS support.
This patchset did not get any traction, probably because it was added as a complete replacement to the buffer_head instead of an incremental improvement.
2018: Dave Chinner xfs: Block size > PAGE_SIZE support
This was the first patchset that came very close in adding Block size >
PAGE_SIZE support in XFS. VFS IOMAP library
came out of XFS as a generic library that provides helpers to interact
with page cache and the storage device. iomap was designed in such a way
to support block sizes > page sizes.
This patchset extended iomap to deal with block size > page size to
circumvent the limitation of the page cache. It adds a new flag:
IOMAP_F_ZERO_AROUND to iomap. This flag tells the iomap layer to zero
the whole block, even if it is a sub-block IO.
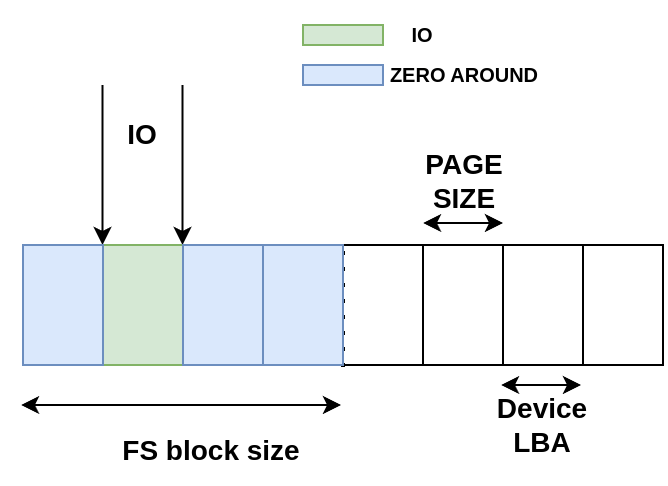 |
|---|
| Sub-block IO requiring zeroing around |
Direct IO: Minimal changes were required to support LBS in the direct IO path. All that needs to be done is padding of zeroes to an IO so that it can occupy the entire block.
Writeback: It is the process used by Linux to write the dirty pages that has been modified in the page cache to be written back to the backing device. For example, before doing a Direct IO on a file range, iomap should first write any of the dirty pages that overlap in this range.
This patchset removes the writepage callback and forces the memory
management (MM) layer to force using the writepages callback. These
callbacks are used by the kernel to write the dirty pages to the backing
device when there is memory pressure. This is the first step to ensure we
can write back multiple pages that belong to one FS block. The minimum
data unit that a filesystem works is a filesystem block(FSB), so it is important
that the whole block gets written on disk instead of partial block writes.
The patch also changes writepages callback by modifying the range to
include the whole “block”:
/*
* If the block size is larger than page size, extent the incoming write
* request to fsb granularity and alignment. This is a requirement for
* data integrity operations and it doesn't hurt for other write
* operations, so do it unconditionally.
*/
if (wbc->range_start)
wbc->range_start = round_down(wbc->range_start, bsize);
if (wbc->range_end != LLONG_MAX)
wbc->range_end = round_up(wbc->range_end, bsize);
if (wbc->nr_to_write < wbc->range_end - wbc->range_start)
wbc->nr_to_write = round_up(wbc->nr_to_write, bsize);
Buffered IO: IOMAP_F_ZERO_AROUND was mainly added to support buffered IO. From the commit message (as Dave chinner is much more expressive than me):
For block size > page size, a single page write is a sub-block
write. Hence they have to be treated differently when these writes
land in a hole or unwritten extent. The underlying block is going to
be allocated, but if we only write a single page to it the rest of
the block is going to be uninitialised. This creates a stale data
exposure problem.
To avoid this, when we write into the middle of a new block, we need
to instantiate and zero the pages in the block around the current
page. When writeback occurs, all the pages will get written back and
the block will be fully initialised.
IOMAP_F_ZERO_AROUND did not make it mainline as the kernel started the
folio conversion around this time, and it solves this zero
around problem from the memory management layer. The final
implementation we got it upstreamed relied heavily on large folio
implementation.
Even though this patchset did not upstream LBS support, lots of the XFS bugs to support this feature were fixed as a part of this series. This made things easy later to support LBS in XFS.
Conclusion:
All the previous efforts in supporting LBS revolved around 2 things:
- Each allocation in the page cache matches the FSB.
- No partial FSB should be written to the disk at any point.
In the next post, I will cover the final LBS support that is in the process of getting mainlined soon.
Happy reading!
References:
[1] Large blocksize support [2] This is a snapshot from 2.6 kernel. Newer versions have more fields.